Mario Klingermann ne définit que trois catégories dans sa
classification, mais il est intéressant de rapprocher les productions
faites par les GAFAM, car avec les laboratoires de recherches,
ils sont auteurs des algorithmes et des bases de données.
Deepmind, start-up fondée par le neuroscientifique
Demis Hassabism et rachetée par Google, est spécialisé dans la
recherche en Machine Learning. Elle conserve dans chacun des
objets de recherche une forme de concurrence et de compétition par le
jeu.
En effet, après la défaite de Lee Sedol face à Alpha go en 2016,
DeepMind entreprend avec alpha zéro de s’attaquer au jeu
d’échecs — domaine largement surpassé par les IA depuis la défaite de
Kasparov. Boris Beaude précise : « Ils ont généralisé ce modèle pour
qu’il fonctionne sur n’importe quels jeux. La machine a atteint le plus
haut niveau de jeu en neuf heures d’apprentissage1 ».
Puis avec Alpha Star en 2019, l’entreprise entraine un
algorithme à devenir le meilleur joueur au monde de
StarCraft II (2010) en le faisant affronter les meilleurs
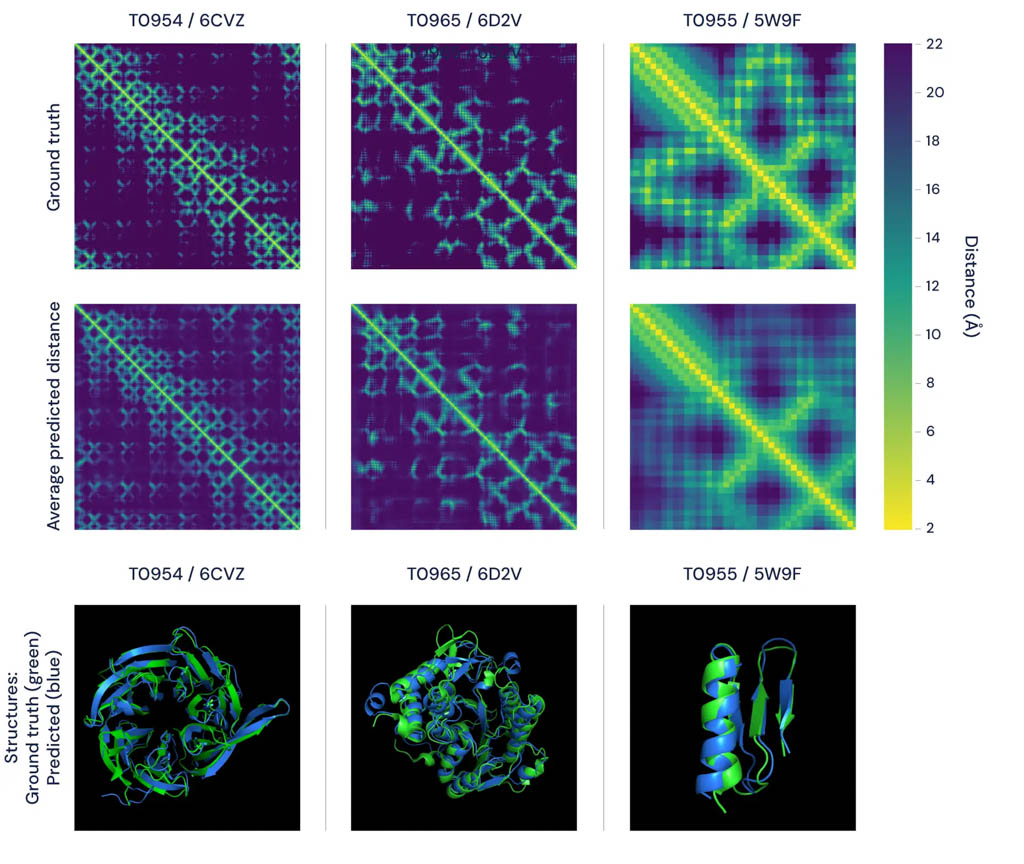
joueurs mondiaux. Dernièrement avec Alpha Fold (2018) puis
Alpha Fold 2 (2020), nous ne sommes plus à proprement parler
dans une forme de jeu, mais dans une forme plus en retrait qui reprend
les mêmes composant. En effet, si l’on se réfère à Roger Caillois,
l’entreprise de DeepMind dans ce domaine reprend les six
critères qu’il définit
pour qu’une activité soit considérée comme un jeu2.
Ainsi : « Le jeu est une activité libre », la filiale de Google
a choisi de participer au concours. « Une activité séparée, qui se
déroule dans un temps et un lieu propre3 » —
ici il s’agit d’un concourt, donc bien séparé dans un espace et un temps
défini. Les résultats de l’algorithme ne sont pas préalablement définis
ce qui confère le statut d’activité incertaine. Il s’agit aussi
d’une activité improductive les données produites n’ont pas
d’application directe, il s’agit de recherche. La compétition
CASP propose une activité réglée, le concours suit une
procédure et des règles strictes quant au déroulé de l’évènement. « Le
jeu est activité fictive, instituant une réalité seconde par
rapport à la vie ordinaire4 » — l’algorithme opère
bien dans une autre réalité : Dominique Cardon précise que « Les
machines prédictives installent un calculateur sur un
monde en lui conférant un horizon5 ». Le terme de
monde instaure bel et bien une distinction entre notre monde et
celui de la machine. Alpha fold joue à prédire le réel. Ce
système de compétition permet un discours médiatique de la part de
Google : à chaque fois, le géant « écrase » la concurrence et montre son
hégémonie dans le domaine du deep learning — dont il propose des
services de cloud computing avec les Tensor Process
Unit (TPU) — puces informatiques dédiées au calcul de machine
learning.